At the beginning of January 2024, NIIS kicked off a proof of concept (PoC) to develop a new major version, X-Road 8 “Spaceship”, which nurtures the proven ecosystem model and security while it takes X-Road to the next level by providing a solid data space infrastructure.
With the proof of concept, NIIS aims to validate the feasibility of replacing X-Road's custom protocol stack with standard data space protocols and align X-Road's trust framework with the Gaia-X trust framework. The project also tries to ensure smooth integration with previous X-Road versions for backwards compatibility, estimate the changes required for information systems when transitioning to X-Road 8, and assess potential changes to existing X-Road components.
In this blog post, we explore the current status of the PoC project.
Support for the standard dataspace protocol
Since the February update, we have continued to work with supporting SOAP services, caching contract negotiation results, defining access permissions using ODRL and message signing and logging.
Caching contract negotiation results
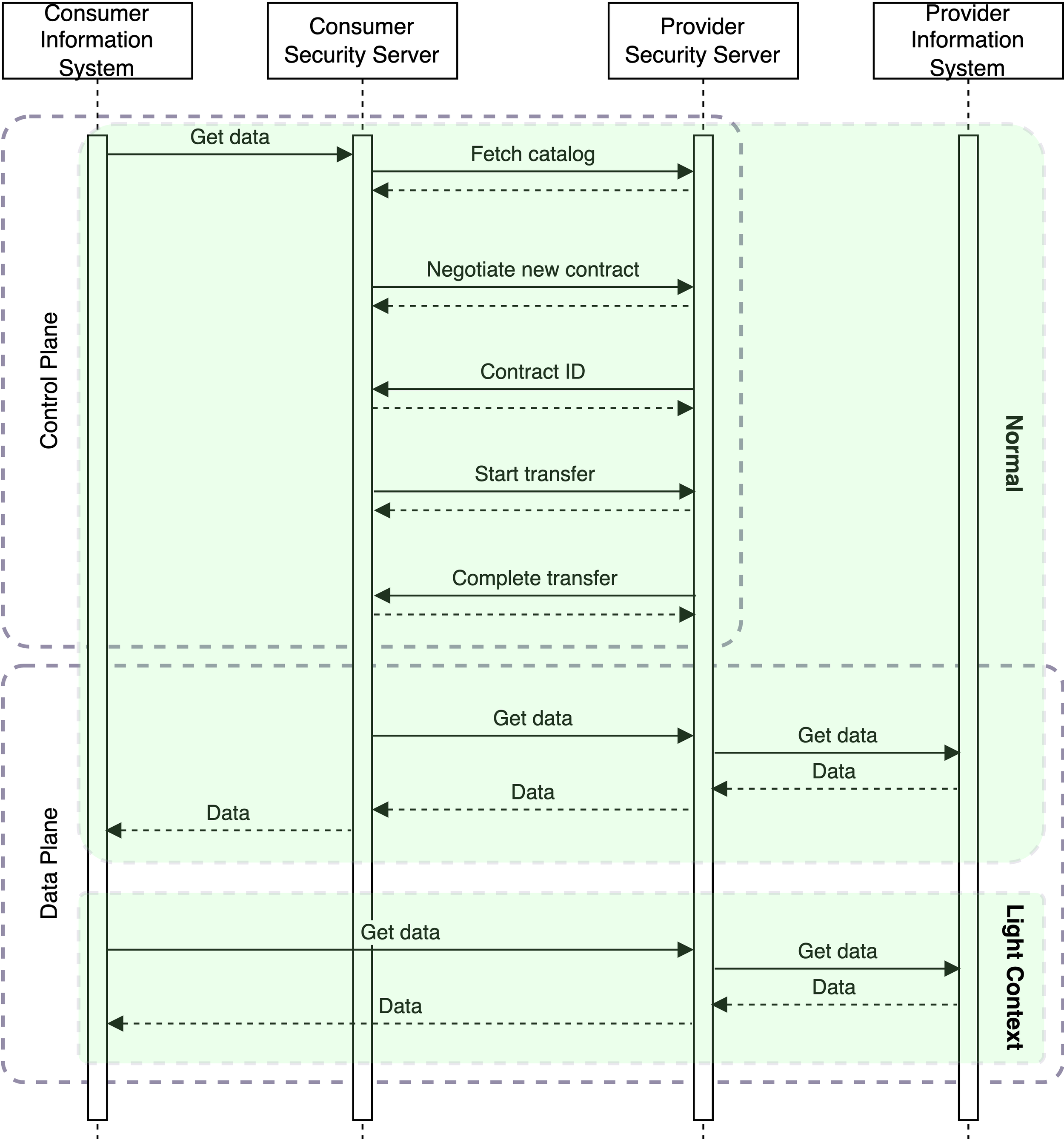
The PoC implementation has been improved by caching and reusing the control plane contract negotiation results. Before, every service request included a complete contract negotiation process that caused several requests back and forth between the data exchange parties. Now, contract negotiation is required only if the service consumer still needs to get a valid access token. In that case, the contract negotiation process is completed, and the consumer receives an access token that can be used for unlimited requests until the token expires. Once the token has expired, the contract has to be renegotiated, and a new access token is generated. Currently, the token is valid for 10 minutes, but the value will be configurable.
Defining access permissions using ODRL
The EDC defines access policy definitions using the Open Digital Rights Language (ODRL). In X-Road, access policies are defined using client identifiers, service codes, HTTP verbs and request paths. An X-Road-specific ODRL profile that extends the ODRL core was implemented to support the current X-Road functionalities. The current PoC implementation supports individual clients and global groups. Instead, local groups still need to be supported. Also, the access rights are maintained in the old Security Server configuration database and periodically exported to ODRL. However, the current implementation already demonstrates that ODRL can support X-Road's access policy definitions and that migration from the current storage format to ODRL can be automated.
Supporting SOAP services
After the latest changes, the PoC implementation supports X-Road's current REST and SOAP interfaces. However, not all the details have been implemented in the PoC, e.g., support for the request hash response header. Nevertheless, existing REST and SOAP service consumer and provider information systems can be connected to the PoC without any additional changes. In other words, it seems that it’s possible to keep the REST and SOAP interfaces fully backwards compatible.
Support for TLS
Initially, connections between two X-Road 8 Security Servers used plain text HTTP connection. The implementation has been updated to use TLS with some of the features already used in X-Road 7.
A provider Security Server must have an authentication certificate issued by an approved Certificate Authority (CA) and registered on the Central Server. A consumer Security Server verifies the certificate and checks its association with the provider Security Server in the global configuration. Instead, in the PoC implementation, the provider Security Server doesn’t verify the consumer Security Server’s authentication certificate. In other words, the PoC implementation doesn’t support mTLS between X-Road 8 Security Servers even though it’s enforced between X-Road 7 Security Servers.
How trust in TLS certificates is currently implemented in X-Road is very X-Road-specific. The issuer of a TLS certificate must be defined as trusted by the X-Road operator, the issuer must be included in the global configuration's trusted list, the TLS certificate must be registered on the Central Server and associated with the Security Server that's using it, the association must be included in the global configuration, and the certificate must have a valid OCSP response. The current implementation adds an extra layer of trust and security, but the downside is that it's not interoperable with other data space technologies. The available data space specifications do not say anything about TLS certificates. The default assumption is that a commonly trusted CA should issue them, but data space-specific exceptions are possible.
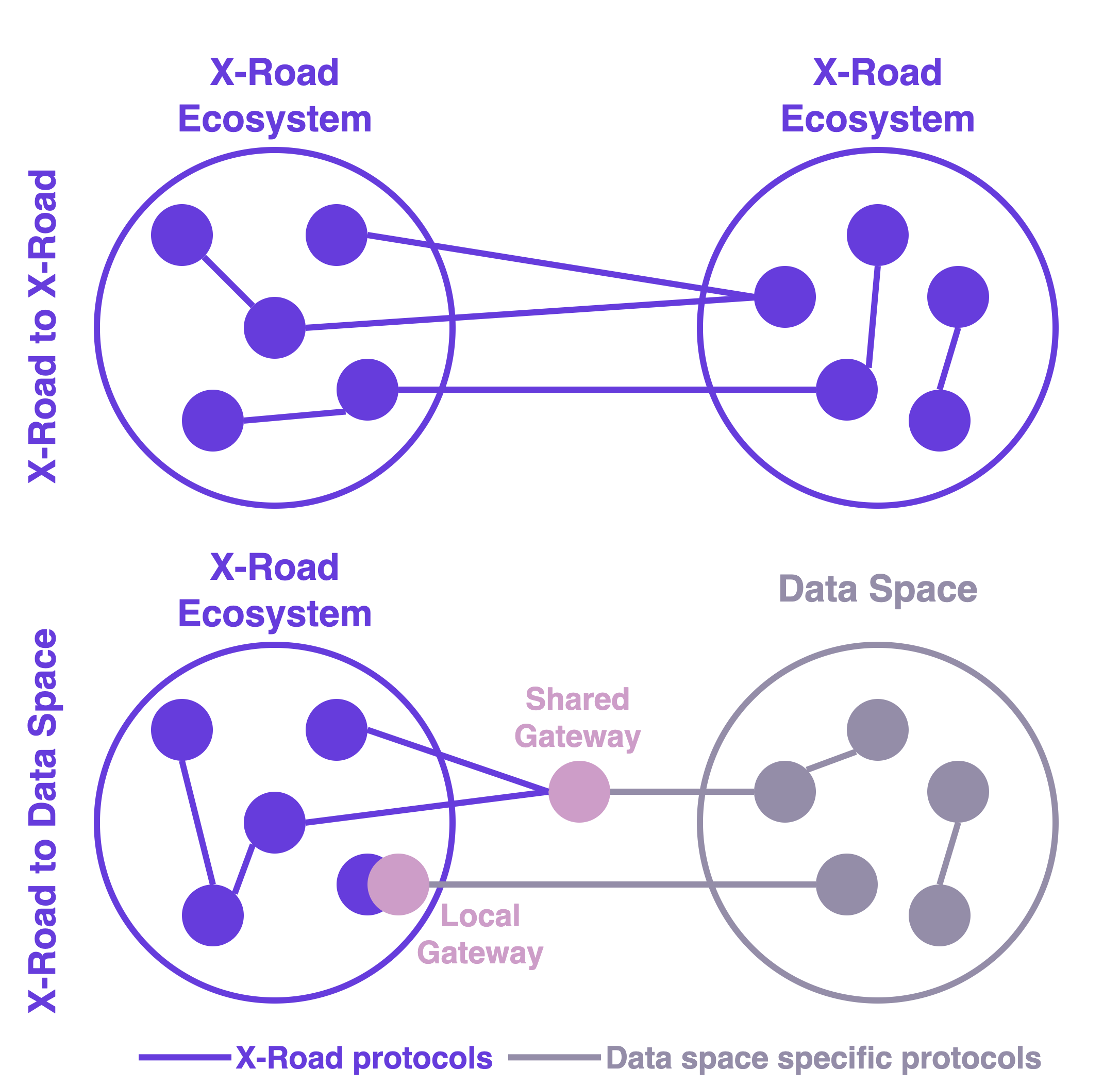
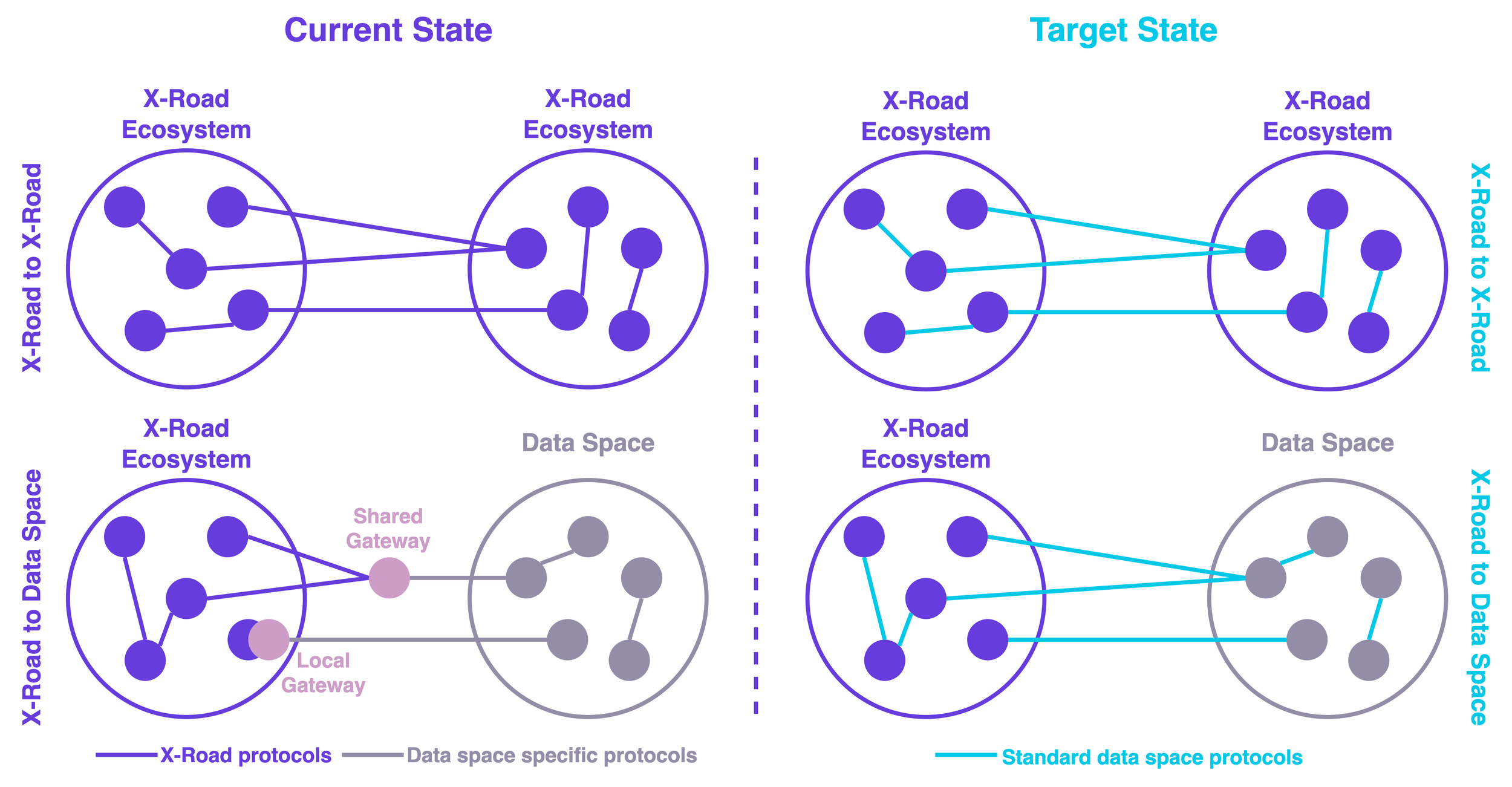
Nevertheless, in X-Road 8, it's necessary to reconsider the X-Road-specific additional layers. At least they should be limited on the data plane level so that the trust and control planes remain interoperable with other data space technologies. Otherwise, X-Road is not interoperable with other data space technologies, even if they're based on the same standards and specifications.
Message signing
Another X-Road-specific feature is the signing, logging and timestamping of messages. In March, support for message signatures was implemented in the PoC. The implementation uses the Digital Signature Services (DSS) Java library provided by the European Commission. In practice, signatures and sign certificate OCSP responses are passed in HTTP headers, meaning a separate transfer or wrapper message between the Security Servers is no longer required. The implementation uses the JAdES-B-LT signature, while currently, X-Road 7 uses XADeS signatures. However, the PoC implementation has some limitations compared to the signatures in X-Road 7. In the PoC, the message body and most of the HTTP headers are signed, while in X-Road 7, the signature covers HTTP verb, request path and URL parameters too. Also, batch signing is not supported, and therefore, each message is signed separately.
Message logging
The PoC implementation doesn't support message logging yet because the current timestamping implementation is incompatible with JAdES signatures. However, adding support for timestamping is possible, but it just requires additional work that may not be included in this PoC.
Before proceeding with the implementation, a more thorough analysis of different logging options is needed. For example, the International Data Space Reference Architecture Model version 4 (IDS-RAM 4) by the International Data Spaces Association (IDSA) defines a different approach to logging. According to IDS-RAM 4, the IDS Clearing House logs information relevant to clearing, billing, and usage control. The Clearing House is an intermediary that provides these services to all data space participants. In X-Road, the Clearing House would be the Central Server or a separate component operated by the X-Road Operator.
The data logged by the Clearing House should not include a complete message with payload but only message hashes, signatures and other non-sensitive information needed to identify the data exchange parties and verify the data's integrity. Instead, it's the responsibility of the data exchange participants to store the entire message and other related information required to verify the hashes and signatures. However, a common standard or technical specification defining implementation details for capabilities provided by the Clearing House does not exist.
Instead, in eDelivery, the evidence of data exchange is implemented using AS4 Receipt – an AS4 message that provides non-repudiation of origin and receipt at the level of message exchange. However, the AS4 Receipt doesn't include sensitive data, e.g., the message payload. Instead, the data must be stored separately by the data exchange parties.
X-Road 8 is expected to provide a solid data space infrastructure, so the Clearing House approach to logging should be followed. Since a common standard or technical specification defining the implementation details is currently missing, there's a lot of room for interpretation. From the X-Road members' point of view, the main difference to the current message log implementation is that the message log currently stores all the details required to resolve a dispute. In contrast, the Clearing House approach requires storing part of the evidence separately in an external system.
However, the current message log implementation and the Clearing House approach aren't mutually exclusive. X-Road could follow the Clearing House approach and continue to support the current logging method. In other words, logging could be configurable so that X-Road members can decide which logging alternative to use based on the data exchange use case - or both simultaneously. Service usage policies could be used to set requirements on the logging level that must be used when accessing a specific service. In this way, it would be up to the service provider to define the required logging level for both data exchange parties.
However, logging-related questions are more than just technical since multiple legal and organisational aspects define requirements for the technical implementation. Therefore, the topic needs to be studied more detail to understand the relevant constraints better.
Support for the Gaia-X trust framework
We have set up an internal instance of the Gaia-X Digital Clearing House (GXDCH) services to have more flexibility. The instance includes Gaia-X Registry, Gaia-X Compliance, Gaia-X Notary and Gaia-X Wizard. Also, we have configured an instance of the X-Road Test CA as a trust anchor, enabling us to issue our own certificates trusted by the GXDCH services. Now, we can issue Gaia-X credentials that we can use for testing purposes.
What’s next?
Next, the main challenge is integrating the Gaia-X trust framework with the EDC based X-Road 8 Security Server. The integration includes looking into supporting X-Road's current trust framework and Gaia-X trust framework in parallel since backwards compatibility is required.
In practice, the next step is to set up the EDC Minimum Viable Dataspace (MVD) example that uses credentials issued by the latest version of the GXDCH services. It includes using the EDC Identity Hub component to store Gaia-X credentials and using them in contract negotiation and defining access control policies. Once the MVD setup has been successfully completed, the same changes can be applied to the X-Road 8 Security Server. Finally, the Gaia-X trust framework must be connected with the EDC control and data planes so that all the planes work seamlessly together.
More blog posts about X-Road 8 and the proof of concept will follow. Stay tuned!